One Lead's Journey to Successfully Improving My Software Forecasting With Monte Carlo Simulation
What is this?
Forecasting is not a skill I use frequently, which means it takes me time to remember each of the steps and the small details I’ve forgotten. There’s a lot of great information out there, but reading it and refreshing my memory takes longer than I’d like it to. My goal here is to describe the process I use to make this easier in the future (i.e. not the why, but the how). And if someone suggests improvements to my process, all the better!
Don’t worry if you aren’t familiar with some of these terms and tools - I’ll link to explanations as each is used.
One final note before we get started: risk management and recording assumptions are a crucial part of delivery forecasting. That should be done in parallel with these steps.
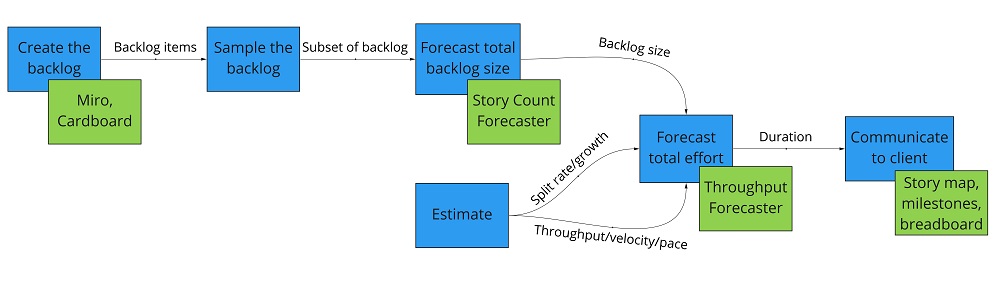
Step 1 - create the backlog
Everyone has their own way to do this part. My preferred method is Story Mapping(Jeff Patton on User Story Mapping, Hate Estimating? Try doing a User Story Map instead) using Miro.
Step 2a (optional) - sample the backlog
A key component of a forecast is the size of the backlog. Ideally we would estimate the size of every backlog item.
When that’s not feasible, we can use sampling to reduce the backlog-to-be-sized to a manageable amount (Sampling, an Introduction and Sampling, probability and certainty, Sampling, probability and certainty) with a minimal impact on forecast quality. More samples means higher confidence that the samples are representative of the whole, but also takes more time to size.
| Samples | Probability the next sample falls within the previously seen range |
|---|---|
| 2 | 33.3% |
| 3 | 50.0% |
| 4 | 60.0% |
| 5 | 66.7% |
| 6 | 71.4% |
| 7 | 75.0% |
| … | … |
| 11 | 83.3% |
| … | … |
| 20 | 90.5% |
| … | … |
| 30 | 93.5% |
When possible I use 20 samples (90.5%), but 7 samples (75.0%) or 11 samples (83.3%) will still get good results.
Step 2b - estimate the size of the sampled backlog items
In my experience, the best results come from splitting the backlog items “as small as possible and no smaller” - it’s easier to estimate small stories. If we can take that one step further and make them all “close enough” to the same size, we can simply use story count - no size estimation necessary.
When that’s not feasible, relative sizing works well. I like to use a simple small/medium/large scale. In the following steps we’ll need numbers, however, so I use a simple scale: small (2), medium (4), large (8). You may be wondering “a small story is 2 what? hours? days?” - and the answer is that it doesn’t matter. The important part is that they express the relationship between the size of stories. As long as we’re careful to use the same units later on, the math works out.
You may be wondering “aren’t these story points?”. I avoided that phrase because there’s so much baggage around it in the Agile world. There’s no need for anything complicated here.
Troy Magennis has a Worksheet with more guidance on methodology and an entire chapter in his book for even more depth. He also discusses the tradeoff between story points and item count.
Step 3 - forecast the size of the backlog
Download a copy of the Story Count Forecaster. This tool takes as an input the sampled backlog items and their sizes, performs a Monte Carlo analysis, and forecasts the total backlog size.
On tab 2 (Enter Features or Epics Here): enter the list of sampled backlog items along with their size
On tab 3 (Forecast Story Count or Points):
- How many total features do you want to forecast?: the total number of backlog items we want to forecast
- What rate do you expect work to split?: enter 1.0 for both the low and high - we will account for split rate in step 4
The key here is to keep our units consistent. If the samples were sized with story points, then the output here will be in story points. If we use story count, then the output will be a number of stories. The output value is always pre-split units of work (see step 4 for split rate).
Choose confidence levels that match your client’s risk tolerance. Lower confidence sets the lower bound for total backlog size, similarly with higher confidence. I usually use 75% and 95%.
Step 4a - estimate split rate (growth)
Experientially, I’ve found these to be good starting range for split rate:
- 0.75 - 1.5 for a well-oiled team, low complexity product
- 1.5 - 2.5 for a new team, low complexity product
- 2.5 - 3.5 for a new team, high complexity product
From that starting point, adjust up or down based on factors such as:
- Is there a reason to expect a higher-than-normal amount of rework, defects/bugs, etc.?
- Do we expect risks to be realized with less lead time or warning than usual?
- Is the feedback or release cadence going to be longer or shorter than usual?
- How many external dependencies does the team have?
Troy Magennis has a Worksheet with more guidance and an entire chapter in his book for even more depth.
Step 4b - estimate velocity (throughput) (pace)
Velocity, throughput, and pace are closely related, but distinct, concepts which are often conflated. Each has their use and what is important is that the units are consistent with steps 2 and 3. I’ll use velocity for now, but mentally substitute the other terms as it makes sense for your context. I think velocity has the largest impact on the accuracy of forecasts, so it’s worth taking some time to get reasonable values here.
It’s best to use historical data when possible, if that historical data is recent. If that isn’t available, this is a guess based on experience. Either way it must be in the same units as backlog size. For time I usually use one week to simplify communication with the client. This is just for expectation setting, and the actual development effort can be done in weeks, sprints, etc.
Once we have a baseline velocity, adjust up or down based on factors such as:
- Will all of the team be starting on day 1, or is there a ramp up period of time?
- Will the team members be working solo, in pairs, a mob, or some other style?
- Are there any constrained or only partially available team members?
- How many external dependencies does the team have?
- Is there any known time off (holidays, vacations, etc.)?
Speaking of external dependencies, identifying and understanding them is a prerequisite for forecasting. If that wasn’t done as part of step 1, spend some time on that before proceeding.
Troy Magennis has a Worksheet with more guidance.
Step 4c - forecasting the delivery
Download a copy of the Throughput Forecaster. This tool takes as an input the backlog size, split rate, and velocity, performs a Monte Carlo analysis, and forecasts the duration with varying levels of confidence (answering the question “how long will it take to build this backlog?”). If the client instead wants to know “what scope can I get with a fixed budget?”, use the Multiple Feature Cut Line Forecaster.
On tab 2 (Forecast):
- Start Date: use what makes sense - what really matters to most clients is cost, which is driven by duration
- How many stories are remaining to be completed?: the total backlog size range from step 3
- Stories are often split before and whilst being worked on. Estimate the split rate low and high bounds.: the split rate range from step 4a
- Throughput. How many completed stories per week or sprint do you estimate low and high bounds?: the velocity range from step 4b
- Throughput/velocity data or estimate is for: use the same units for time
The output is a range of durations based on confidence/likelihood.
Step 5 - delivering the forecast
At this point, we have a forecast of duration (i.e. a range of durations along with their likelihood), therefore we can forecast cost. If we have a likely start date, we can also forecast the delivery date. However, none of this is useful unless we can communicate it to the client.
The most straightforward deliverables would be:
- A representation of the backlog that was used in the forecast (e.g. a story map with “in this release” and “out of this release” clearly delineated)
- The forecast - duration, cost, date
- Assumptions that are integral to forecasting - consistent team size, uniform distribution of split rate and velocity, etc.
- Assumptions and risks are specific to this forecast - e.g. does the team need hardware or an environment to start working on a feature?
- How forecasting works and what confidence means (i.e. how to interpret the likelihood of the forecast range)
If the client is already familiar with forecasting, we could even give them the tools (e.g. spreadsheets, estimates, etc.) used above.
However, my team has been experimenting with some other ways to communicate the results, which I’ll cover in a future blog post.